Industrial Video Intelligence, Reimagined: Ailytics Deploys NVIDIA Cosmos 3 Across Heavy Industry
June 2, 2026
Ailytics deploys NVIDIA Cosmos 3, the latest unified OmniModel across Ailyssa, our AI platform, to deliver semantic search, periodic scene reasoning, alert reasoning, and spatio-temporal standard operating procedure (SOP), monitoring on existing CCTV infrastructure across construction, manufacturing, maritime, and logistics.
Figure 1: LVM Reasoning Capabilities
Ailytics is a Singapore-headquartered Vision AI company with over 400 deployments across 11 countries, today announced the initial deployment of NVIDIA Cosmos 3 across its Ailyssa platform.
Ailyssa converts any existing CCTV infrastructure into a real-time safety and operations layer for heavy industry, with enterprise customers including Changi Airport Group, DHL, Laing O'Rourke, Woh Hup, Obayashi, Aperoti, Leonardo da Vinci International Airport and PaxOcean.
With Cosmos 3 embedded into four core capabilities of the platform, Ailyssa now combines the speed of traditional embedding computer vision techniques with proprietary tooling and the contextual reasoning of a state-of-the-art vision-language model, purpose-built by NVIDIA for the physical world.
“Traditional Vision AI techniques such as detection, segmentation, classification, layered with business logic and our own proprietary techniques remain extremely strong for a large class of use cases, and that's not going to change anytime soon. Where it has always struggled is the long tail of complex, sequential, and contextual scenarios. What Cosmos 3 adds is the ability to reason about a series of events within a view, across multiple views, and against a specific SOP. That is a genuinely new capability for CCTV-based safety in heavy industry, and our job is to make it work cost-effectively and accurately at scale.”
— Tan Wei Zhuang, Lenard, Co-Founder and CEO, Ailytics
“We've built Ailyssa on NVIDIA's full stack from day one — NVIDIA DeepStream, NVIDIA TensorRT, and now Cosmos. With Cosmos 3, what changed isn't just speed — though going from minutes to seconds per inference matters enormously at scale. What changed is that an entire class of use cases we'd previously shelved as unsolvable with traditional CV are now addressable. Sequential SOP verification, contextual scene reasoning, multi-object relationship understanding — these were on our wishlist for years. Cosmos 3's throughput improvements mean we can run these capabilities cost-effectively on live CCTV streams, not just in offline experiments. That's not incremental — it moved an entire category from research to revenue.”
— Prateek Manocha, Co-Founder and CTO, Ailytics
Where traditional Vision AI excels, and where it falls short
Traditional Vision AI is more than detection + business logic. At Ailytics, it is a combination of detection, segmentation, and classification models, layered with business logic and proprietary techniques such as our 2D-to-3D spatial understanding and our methods for handling outdoor, harsh, dynamic environments. For a large class of use cases this stack remains extremely strong, and it is what underpins the majority of the alerts we generate today across our customer deployments.
Where this approach struggles is the long tail of complex sequential scenarios and contextual scenarios. Situations where the answer depends not on what is in a single frame, but on the relationship between multiple objects, the order of events, or the context of the wider scene. For these cases, either the techniques cannot solve the problem at all, or the number of permutations and corner cases is so large that hand-crafting the business logic to cover them would take an impractical amount of engineering time.
The result is not a replacement for our existing perception stack. It is a complement to it. Fast, specialised models continue to do what they do best, and the reasoning model is invoked where context, sequence, or judgement is what the customer actually needs.
Figure 2: Difference between traditional AI vs VLM
Four Ways Nvidia Cosmos Powers Ailyssa
Ailytics has integrated Cosmos into four capabilities inside Ailyssa. Each one targets a specific set of problems that customers in heavy industry have been wanting to solve.
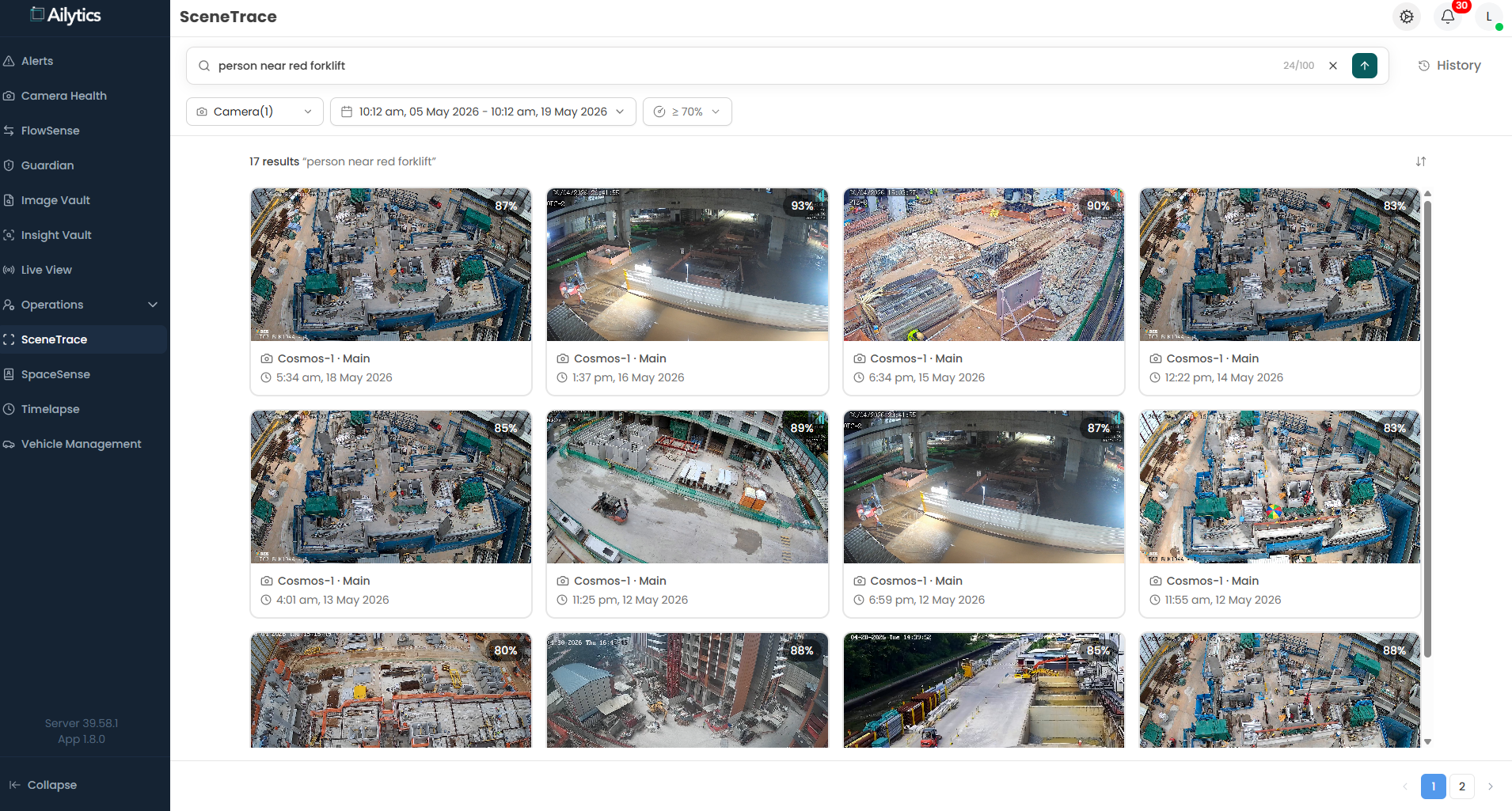
1. Contextual search for complex scenarios
From "find a worker not wearing PPE" to "find a worker standing next to a moving excavator not wearing PPE"
Traditional video search is based on metadata, keywords and classes: find people, find vehicles, find PPE. That works for simple queries. However, it breaks down the moment the question involves a relationship between an object, a person, and a state of the world.
With Cosmos Reason, Ailyssa now supports natural-language scene search across hours of CCTV footage. Customers can ask Ailyssa directly:
Workers positioned under a suspended load on the slab
Personnel standing near unprotected open edges without fall protection
Operators in close proximity to live machinery that is not wearing a red vest
Persons inside a designated exclusion zone while a crane is slewing
Cosmos interprets the scene the way an expert safety officer would, then returns ranked clips based on reasoning explanations to generate alerts. This is not just search, it is searchable judgement, applied retroactively across CCTV recordings that hold valuable information.
Figure 3: Contextual search on recorded footages
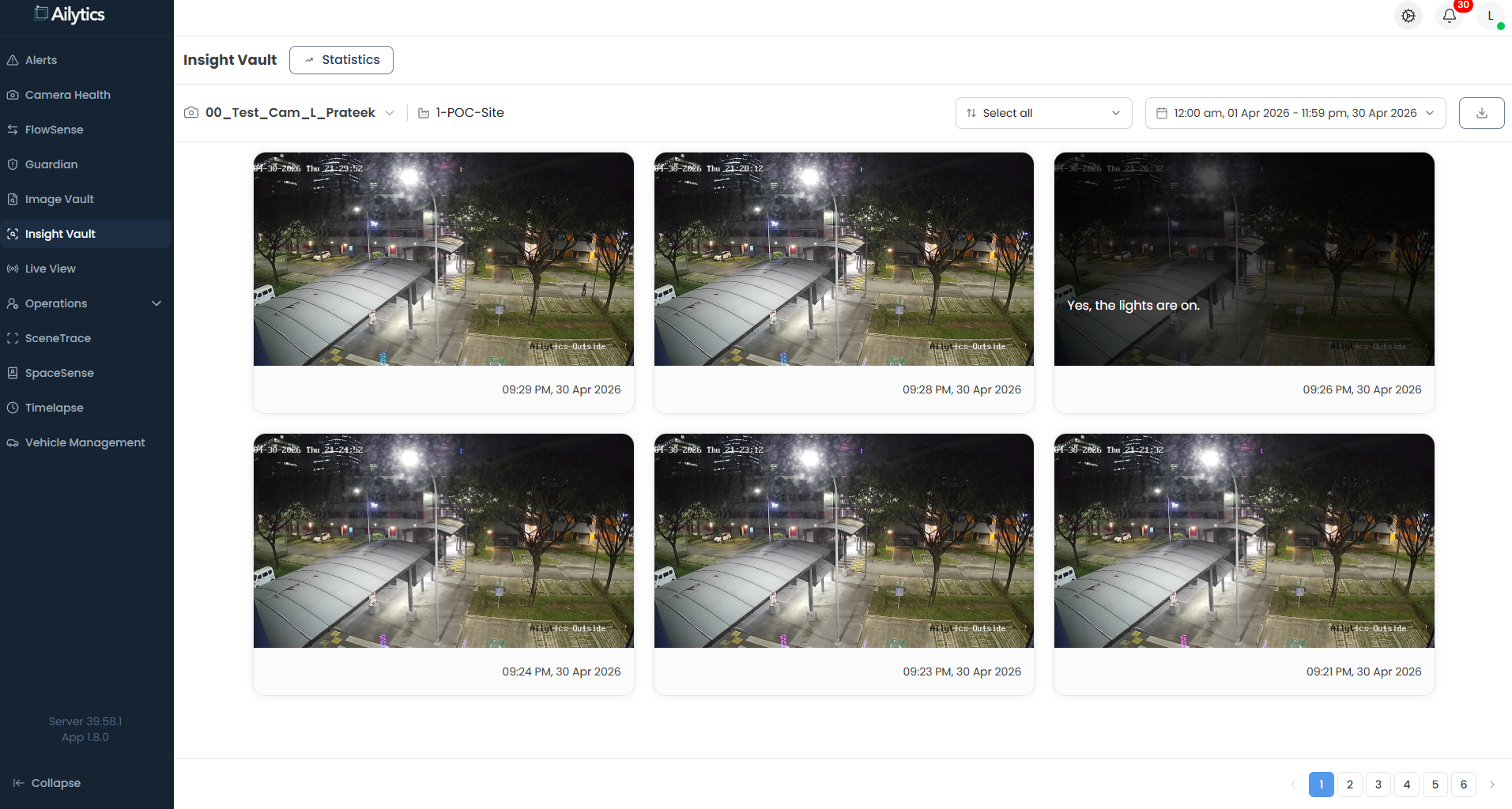
2. Periodic image reasoning for continuous scene awareness
Asking the camera a question every few seconds
Some hazards do not produce a clear trigger event. A spill grows slowly. A safety barrier drifts out of position over a shift. A walkway becomes obstructed by stored materials over the course of an hour.
Ailyssa uses Cosmos Reason in a periodic reasoning mode: at a configurable interval, the system samples a frame from a CCTV feed, runs a structured reasoning prompt against it, and decides whether an alert is warranted. The interval is tuned per use case, ranging anywhere from every few seconds for high-risk zones to every few minutes for ambient housekeeping checks.
This gives operators a continuous, low-noise awareness layer for the slow-moving risks that traditional event-based detection may miss entirely.
Figure 4: Periodic based scene reasoning
3. Second-layer reasoning check on generated alerts
Cutting false positives without raising the confidence threshold
Most Vision AI systems currently face the same trade-off: tighten the threshold and miss real events, loosen it and drown operators in false alarms.
When an alert is generated, for example, a no-helmet alert, a near-miss event, or an exclusion-zone breach, the relevant clip is passed to Cosmos for a structured re-evaluation: is what we're seeing actually the violation we think it is, given the context of the scene?
The reasoning model can catch the cases that traditional Vision AI may struggle with: a red spotlight that looks like a fire, a pair of gloves being held in the hand and not being worn, a worker walking through a zone versus working inside it, a reflection on a piece of metal that looks like stagnant water. The result for customers is a meaningful drop in false positives or unnecessary alerts while keeping detection sensitivity high which directly translates into operator trust and faster response on the alerts that matter.
Figure 5: Second layer AI validation
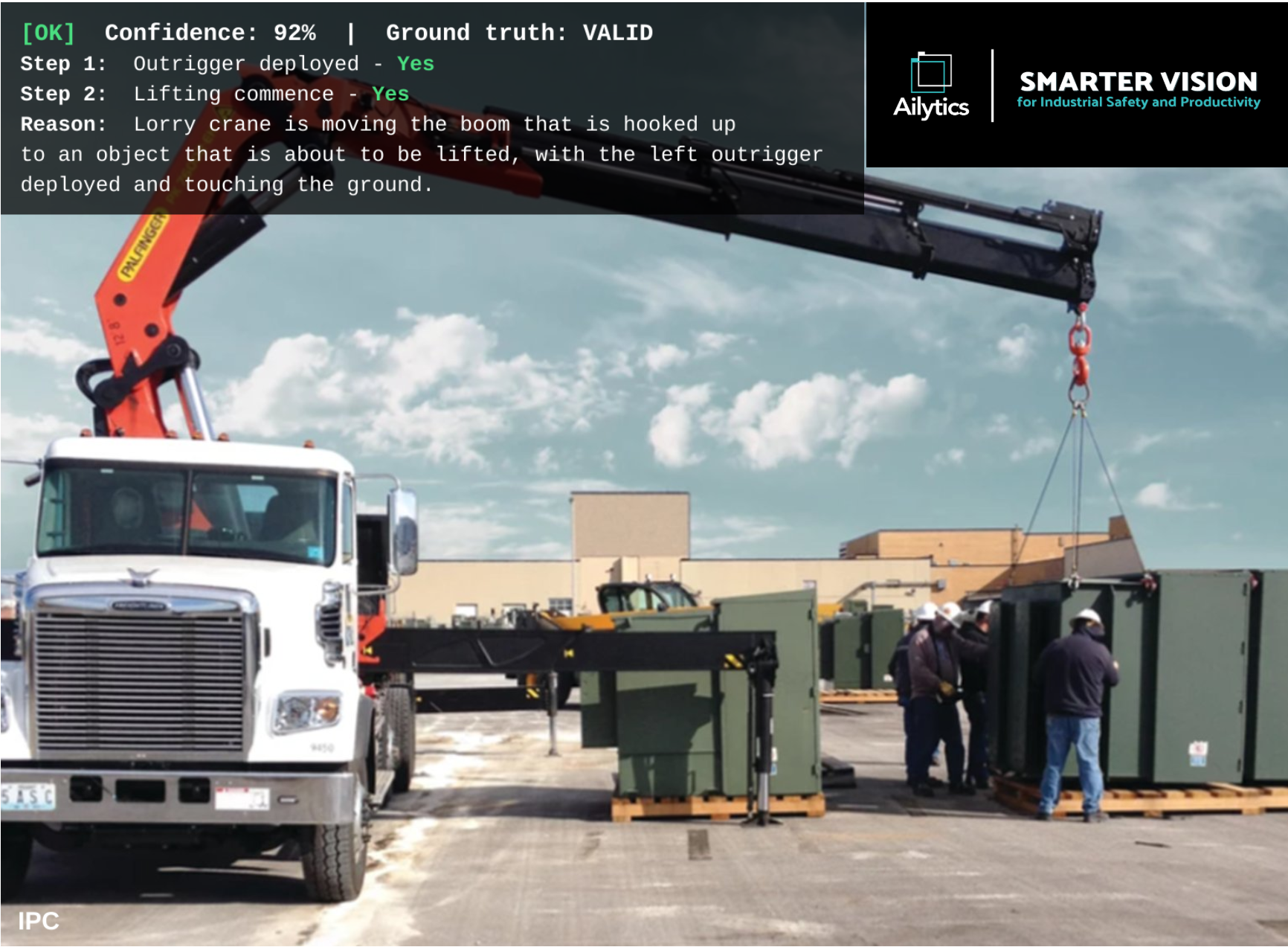
4. Spatio-temporal reasoning for sequence and SOP verification
Did the right things happen, in the right order, in the right window?
Many of the most consequential safety and operational procedures in heavy industry are not single static events, they are sequences. A lorry crane can only begin to lift once its outriggers are fully deployed. A moving plant must be escorted by a banksman. When refueling a vehicle there should not be any usage of the mobile phone and the hand must remain on the nozzle throughout.
Ailyssa uses the spatio-temporal reasoning capabilities of Cosmos to verify these sequences against site-specific SOPs. The model reasons across the entire frame across a series of frames and not just a particular event in an isolated part of the frame.
When the sequence does not match the required SOP, Ailyssa flags it not as a hard violation, but as a structured deviation analysis that supervisors and safety managers can review.
Figure 6: Temporal reasoning of scenario
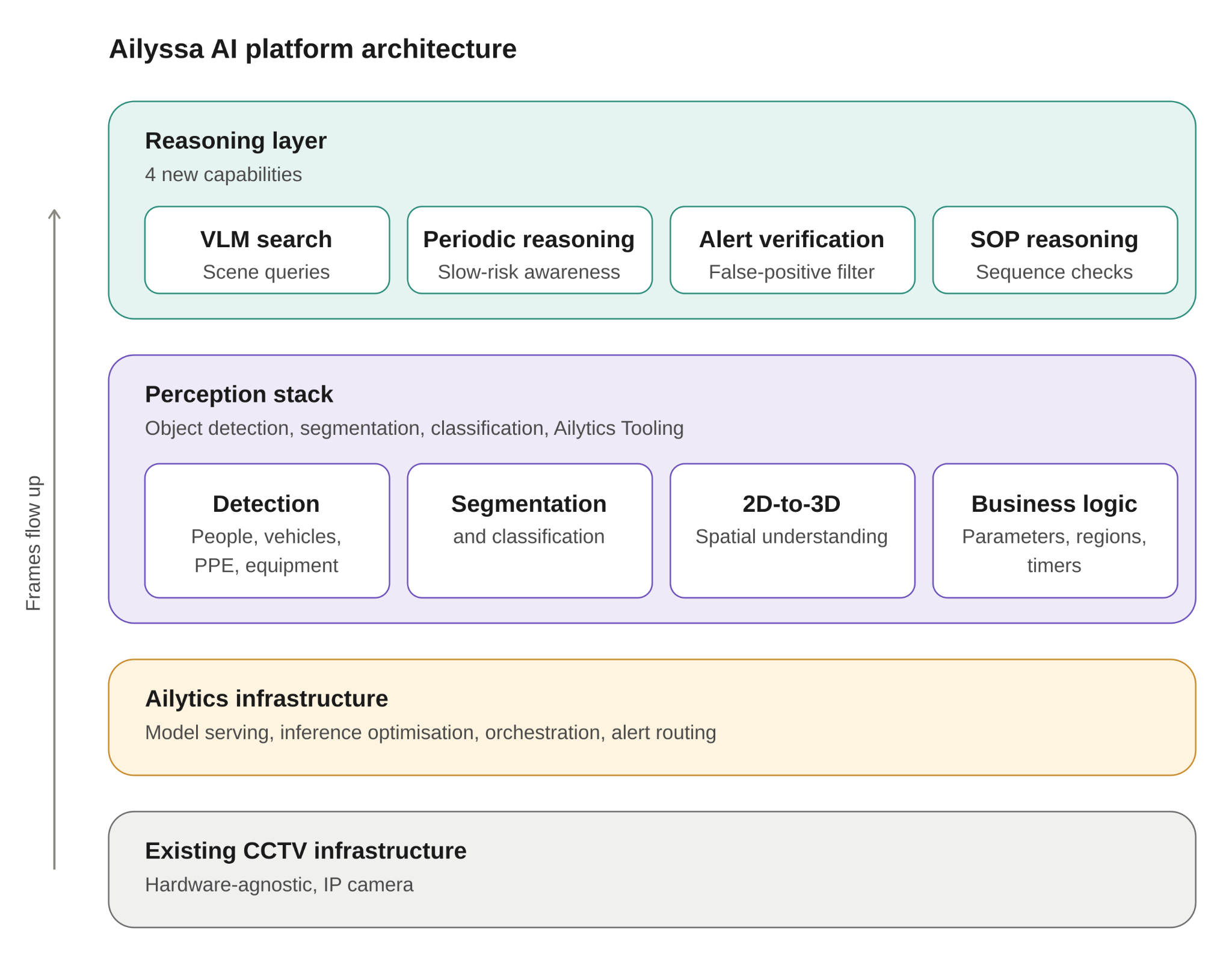
How it fits into the Ailyssa platform
Cosmos does not replace Ailytics' existing capabilities. It complements them. Ailyssa runs a layered architecture where fast, specialised models handle high-volume perception in real time, and reasoning models are invoked selectively for search, for periodic checks, for verification, and for sequence understanding where their richer output justifies the additional compute.
This layered design is deliberate. It preserves the latency and cost economics that have made Ailyssa affordable and accessible to organizations around the globe, while solving an entirely new suite of use cases that were previously out of reach for traditional Vision AI safety systems.
Figure 7: Ailyssa Architecture
Cosmos Reason 2 and Cosmos 3, what changed, and why it matters to us
NVIDIA has iterated the Cosmos family rapidly, and each version has unlocked specific things for our platform. Below is a practical comparison from the perspective of a company deploying these models into our customers in heavy-industry environments.
Cosmos Reason 2
Cosmos Reason 2 was the first version of the family that Ailytics deployed into customer environments. A reasoning vision-language model built on the Qwen3-VL backbone and post-trained with supervised fine-tuning and reinforcement learning for physical AI, it brought enhanced spatio-temporal understanding, 2D and 3D point localisation, bounding box outputs with reasoning explanations, OCR, and a 256K-token context window. Cosmos Reason 2 is the current number-one open model on Physical AI Bench and Physical Understanding Bench, outperforming significantly larger open models. For us, it was the first reasoning VLM that produced outputs structured well enough to drive real customer alerts on a real CCTV stream.
Cosmos 3
Cosmos 3 is the leading open omni model with native vision reasoning, enabling vision AI agents to perceive, reason, plan and act in the physical world. It delivers industry-leading world understanding for vision AI agents, advancing safety monitoring, traffic alerts, and dense captioning across smart cities, industrial systems, and autonomous vehicles. Power intelligent video AI agents that analyze live streams or pre-recorded videos—capable of detecting and localizing events, generating alerts, answering questions about footage, producing summaries, and using reasoning to perform root cause analysis. Useful across public safety, traffic monitoring, logistics, and quality inspection.
At-a-glance comparison
Note: The comparison above reflects our current assessment based on early access to the model.
Figure 8: Cosmos-Reason 2 and Cosmos 3 result comparison
Cosmos3 Excels At Speed, Grounding and Reliability
Speed — by far the most visible improvement. Generation throughput has improved by 1–3 orders of magnitude in practice. End-to-end latency has dropped from minutes to seconds.
Reasoning-mode stability — Cosmos-3 rarely enters infinite loops in think mode, whereas Cosmos-2 frequently does (often unrecoverably). Cosmos-3 occasionally stalls but the failure rate is far lower.
Visual grounding — Cosmos-3 captions name specific colors, items, and on-screen UI elements (e.g. 'red boundary lines', 'digital screen displays real-time data') that Cosmos-2 typically generalises.
Conciseness — Cosmos-3's detailed caption (140 tokens) carries more verifiable content than Cosmos-2's longer detailed caption (248 tokens), which contains more filler and speculation.
Task completion reliability — Cosmos-3 consistently returns within seconds; Cosmos-2 occasionally fails to return at all (Example 5).
Availability of Features
The four capabilities described in this release are currently in active beta with a select group of Ailytics customers. The focus of the beta is deliberate: we are working through high-value, challenging use cases that have historically been difficult or impossible to solve with traditional Vision AI, using these deployments to assess where Cosmos models perform strongly today, where they need additional engineering or fine-tuning, and where the unit economics work for production roll-out.
Open Invitation: Bring us your most challenging use cases
Ailytics is actively expanding the beta to include more complex, high-value scenarios from customers across heavy industries and critical infrastructure such as construction, manufacturing, maritime, and logistics. If your team is working on a video AI problem that traditional detection, segmentation, and classification models have not been able to solve, particularly one that involves sequential events, contextual judgement across a scene, multi-camera reasoning, or SOP verification, we would like to hear about it.
Customers and prospective partners with use cases of this kind are invited to reach out to the Ailytics team directly. Beta participation provides early access to the new capabilities, hands-on engineering support from our team, and the opportunity to help shape how reasoning AI is applied in your specific operating environment.
About Ailytics Ailytics is a Vision AI software company delivering smarter vision for industrial safety and productivity by leveraging on advanced computer vision to detect risks, improve compliance, and optimize operations across construction, ports, airports, and other heavy industry sectors.
.png)


.png)

